will stedden
will steddenPredicting Bike Share Usage
I recently worked on a Kaggle competition while I was taking Coursera's Introduction to Data Science. Here's a quick summary of what I came up with.
]")
The goal of this project was to come up with a system to predict how many bikes will be used during a given hour.
The bike share company provided us with historical data for two years, including hourly weather and weekend/holiday information as well as the number of bikes in use each hour. I tested my predictions against the hourly bike usage for the last week of every month.
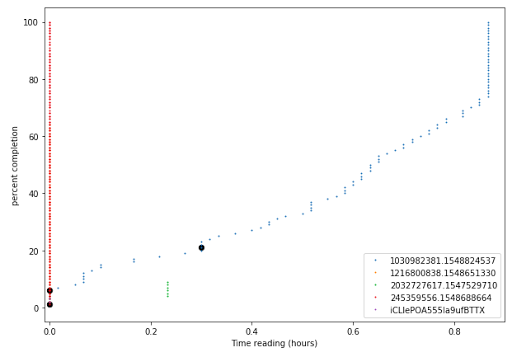
Because there were slowly-varying trends in bike share popularity over this time, I decided that the most important factor was the average for a given hour over the past 5-10 days. I therefore, generated this statistic from the underlying dataset by performing a moving average. I then supplied the weather and holiday statistics along with the moving average as training data to implementations of a neural network and a random forest. The random forest performed better on my cross-validation set so I used it in my submission.
The data set was surprisingly small so I simply imported it into the memory of a MATLAB runtime environment. From there, I used a custom script to generate moving averages for every hourly timeslot and added that to the original dataset. These datasets could be fed directly to existing neural network and random forest packages contained in MATLAB. The data munging to create the moving average presented a slight difficulty.
The approach was simple but still allowed me to improve greatly over the baseline benchmark, reducing the mean error from 1.5 to 0.75. You can check out the biker-predict code on github.