will stedden
will steddenUpdating su_chef object detection with custom trained model
building a custom trained yolov3 model for vegetable detection
As part of my su_chef project, I needed to expand the camera object detection model to include more classes that I am interested in. Originally, I was using the standard YOLOv3 weights file from pjreddie's original. That model has 80 classes that it can identify, but unfortunately, most of them weren't really useful for my use case of finding and picking up fruits and vegetables.
So last weekend, I learned how to fine-tune a YOLOv3 model using my own custom image dataset. It would be impractically slow to train the neural net on my personal computer without a GPU so I used Google Colab to train using their free GPUs.
For the code, I packaged up a tutorial repo (based on this one) that pulls in training data from Google Drive, trains, and then stores trained model directly back into my Google Drive. I also included my example data and a test script to make it easier for others. If you want to try it yourself or adapt it, clone the repo, copy it to your Google Drive, and follow the instructions in the README.md file.
Read on to see how it performed for my task.
Initial Results
To start, I just used some previously annotated data from Google's OpenImages project to get a dataset that includes apples, tomatoes, and bell peppers. After training for 2500 iterations it was doing a fair job at distinguishing between the three on example images like this.

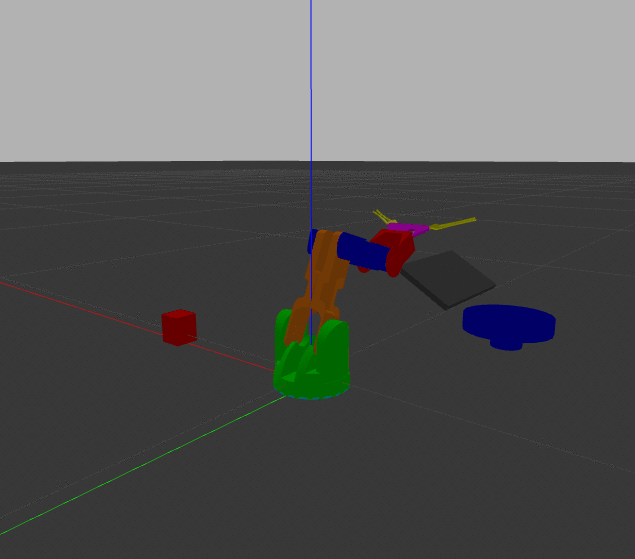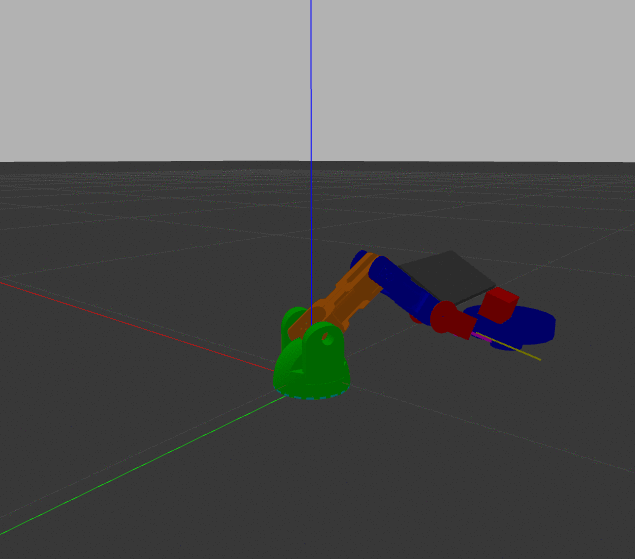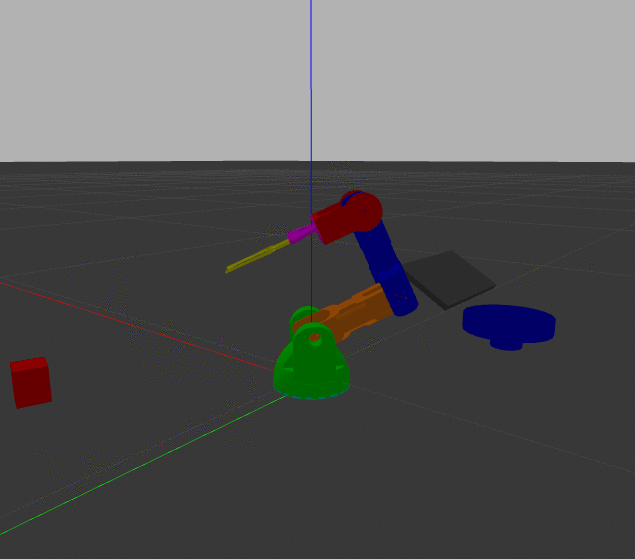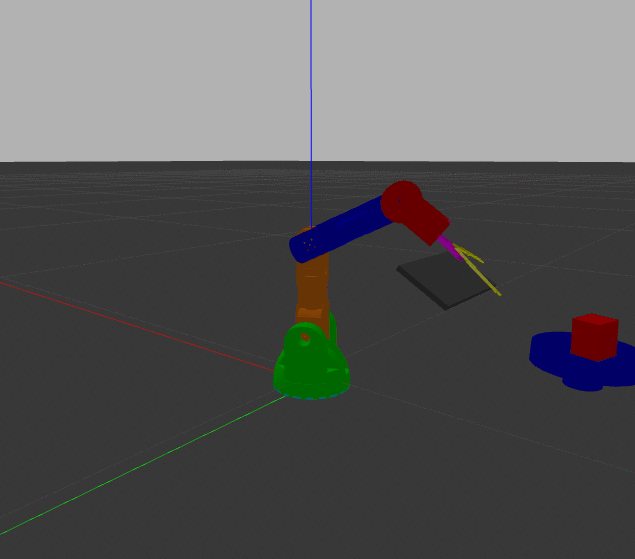
Importantly, because I'm using the Darknet implementation, detection still works in near real-time even on my crappy CPU machine. I incorporated this new model into my ros_braccio_opencv_obj_detect_grab repo and ran just the detection subroutine. It does a decent job of distinguishing between the three.

It isn't quite perfect though, particularly with distinguishing the bell pepper from the tomato. And when I use the new model with the overhead cam and try to pick things up, the performance is markedly worse. Particularly, as shown in this example, the apple is almost always identified as a tomato and the tomato is often mistaken for bell pepper.

Overall, this made the results unsatisfactory. I kept training for more than 3k iterations but the avg loss had stopped improving on the test set, and there wasn't a noticeable improvement. I could take some time and quantify this, but I'm not writing a paper here, I'm just trying to pick up some veggies. I suspect the main failure is coming from the difference between my training data and the images that the overhead cam is providing since the annotated images are much higher quality than webcam images in my actual setup.
Adding more and better training data
To improve my performance I've begun adding more manually annotated data. During this process I learned something about myself.
You know you've found a machine learning project you love when you are willing to annotate your own data.
— Will Stedden (@bonkerfield) July 29, 2020
I took pictures directly from the overhead cam using the fruits and vegetables that we had in the house. Even after just adding just 40 images and retraining for 2k more iterations, I'm seeing some qualitative improvement. Here's a hand-picked (pun intended) example.
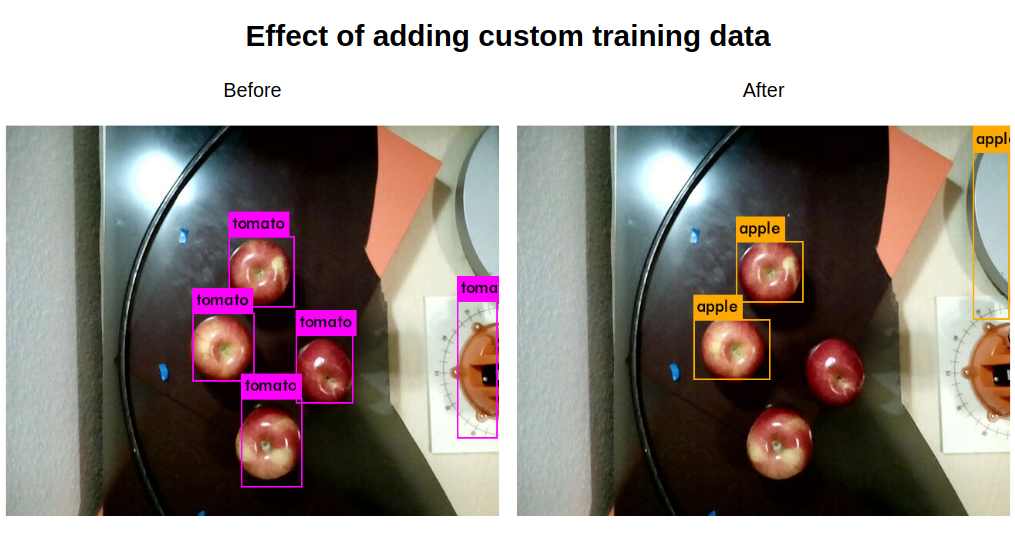
There will always be room for improvement on this type of model, but this is good enough for me for now. I'll continue fine-tuning as needed.
Next steps
At least for now, this lets me update my pickup script to allow targeting of specific objects, which will enable the next phase. As outlined in my last post, the next steps are going to be building my veggie slicer and moving around bowls under the slicer. I've already started on the design of the slicer and I hope to spin that up by end of next week.